
In today’s fast-paced digital landscape, ensuring consistently uninterrupted service for your customers is key. This is particularly vital during application or operating system upgrades, which can often lead to significant disruptions if not handled properly. Traditional methods of maintaining two permanent stacks to avoid downtime can be prohibitively expensive and rife with operational issues. Fortunately, Cloud Elemental have developed a roster of Elements designed specifically to prevent major outages – such as the recent global outage caused by the latest CrowdStrike upgrade.
The CrowdStrike incident highlights the critical need for a robust upgrade strategy. A faulty software update issued by security giant CrowdStrike resulted in an outage affecting Windows computers worldwide. Businesses, airports, train stations, banks, broadcasters, and the healthcare sector were all disrupted, causing mass consumer dissatisfaction. The issue stemmed from a defect in a software update, causing affected Windows computers to crash. While CrowdStrike quickly deployed a fix, the overall recovery process is expected to drag on for many organisations due to the complexity of the fix. For many organisations (including CrowdStrike themselves), the reputational damage of the outage will outlive the financial damage.
Being strategic, proactive, and preventative always pays off. To effectively prevent or remediate potential disaster scenarios, it is crucial to have a robust workflow and strategy in place to ensure your services remain available to customers.
Implementing Seamless Upgrades: Our DRP Elements
Cloud Elemental have developed a range of solutions which allow for effective, preventative Disaster Recovery Planning (DRP), and a seamless transition during your upgrade process. Our EC2 Automation, Blue/Green Deployment, and EC2 High Availability (HA) automations ensure a smooth and efficient upgrade, with safety nets to rollback on potential failures.
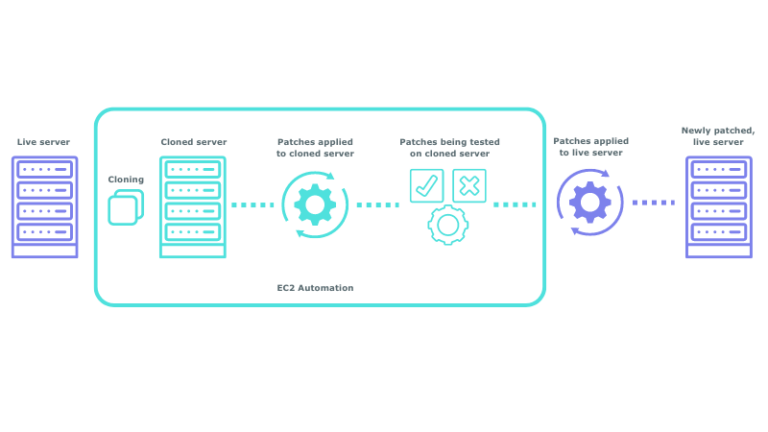
Upgrade on a Clone of Your System with EC2 Automation
Cloud Elemental’s EC2 Automation solution allows you to automatically create a copy of your required production server, cloning them to an isolated network. This allows you to test the new patch before making any permanent changes to your live system. With patches tested on the isolated copies, you no longer have to worry about halting your live servers and disrupting your customers. Here’s how it works:
- Snapshots & Save Points: EC2 Automation creates snapshots of your system, saving them as a “last known good copy” or Save Point.
- Isolated Network Clone: It launches a clone of your system in an isolated network.
- Apply Updates: Patches are applied to the cloned system.
- Security Scans & Testing: The system undergoes comprehensive security scans and smoke tests.
- Manual Approval: Finally, manual approval steps ensure that everything is in order before proceeding.
Only after your system has successfully gone through this process and all tests have been passed should your organisation proceed with the upgrade.
Transition to the Upgraded System with Blue/Green Deployment
Once EC2 Automation has thoroughly tested your new upgrade for bugs, it can be a complex task to transition this to your live system. Various dependencies such as networking, load balancing, databases and shared discs must be considered. This is where our automated Blue/Green deployment comes into play, making the transition fast, efficient, and accurate. Here’s how Blue/Green works:
- Switch to Live Stack: Blue/Green Deployment switches all of our cloned EC2 Automation patched instances to the live stack. Blue/Green Automation takes care of all network changes and makes the seamless switch between the two environments. We automate the switching process, therefore minimising downtime and human intervention, whilst securing the workflow.
- Retain Unpatched Instances: Your previous unpatched instances are retained for quick rollback. If necessary, rollback can be completed within 5 minutes (the time required for Windows and other services to start up).
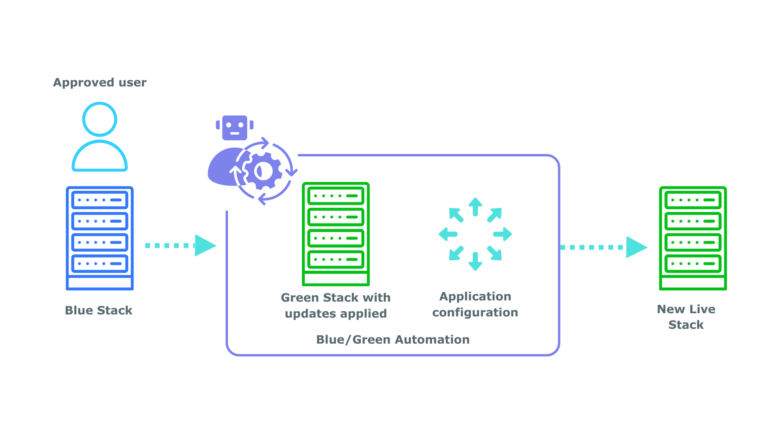
This approach ensures that if a disaster occurs whilst your users are using your application, you can quickly revert to the previous working state without significant downtime.
When used in conjunction with EC2 Automation, the entire process is automatic, and the old stack can be cleaned up to reduce overall costs.
Make a Rollback in Case of Failure with EC2 High Availability
Despite the best preparations, there’s always a chance that disaster could strike. EC2 High Availability (HA) helps you revert your system, along with all its dependencies, back to a previous stable state. Here’s how:
- Launch from Save Points: EC2 HA can launch a stack from one of your previous safe Save Points.
- Configure Dependencies: EC2 HA automatically configures all other dependencies to ensure the system is fully operational before launching.
- Speedy Recovery: EC2 HA allows a Windows Instance to be recovered in under 5 minutes, minimising downtime and ensuring business continuity for your customers.
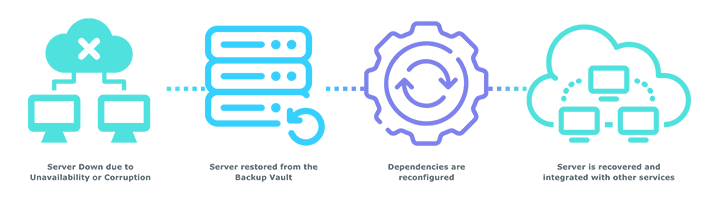
Even if your organisation has not yet adopted our EC2 Automation or Blue/Green Deployment strategies, EC2 HA ensures that you are not left in the dark during an outage. Should your production systems fail during an upgrade and you don’t have precautionary measures in place, EC2 HA can restore your servers from your most recent functionally approved backups. By configuring the necessary dependencies, EC2 HA can bring your production systems back online, making them functional and available to customers in the shortest time possible.

By strategically leveraging EC2 Automation, Blue/Green Deployment, and EC2 High Availability, your organisation can effectively manage upgrades, prevent major outages, and ensure continuous service availability. Want to stay proactive, reduce costs, and maintain a seamless customer experience, no matter what the future holds? Get in touch with us today to discuss how we can help you with your DRP.

