
Servers are not faultless. They can, and often do, suffer from faults caused by everything from human error to disruptive natural disasters. To prevent the common complications that come from server unpredictability, we developed a solution for one of our clients known as EC2 HA. Essentially, it’s our unique approach to ensure that your servers can continue running in the rare event of disaster.

What is EC2 HA (High Availability)?
EC2 High Availability (HA) is a proactive operational solution designed to minimise downtime in the event of server failure within an availability zone (AZ) or a subnet – a rare but devastating scenario for an organisation. It acts as a safety net by restoring EC2 instances in the same subnet; restoring EC2 instances from one subnet to another; or restoring from one AZ to AZ to another in the event of unavailability.
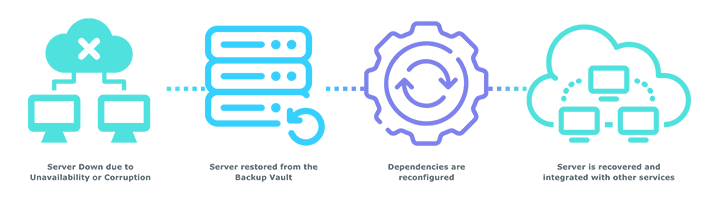
This process involves restoring the most recent backup of each EC2 instance from a Backup Vault to a different subnet in your selected AZ.
How Do Our Clients Use EC2 HA?
EC2 HA became incredibly useful when our client wanted to create a new test environment for their servers. They needed their new environment to operate in a completely different subnet to guarantee high availability. As a key player in the energy trading industry, downtime was absolutely not an option for our client. Every minute of downtime would cost our client thousands of pounds of revenue – not to mention reputational damage.

With our EC2 HA solution, we were able to seamlessly create a carbon copy of our development servers and re-launch them in a new subnet. This, in turn, created a new test environment. The new servers were configured and calibrated automatically as part of the EC2 HA process. Utilising their new test environment, our client was able to streamline application changes quickly, eliminating bottlenecks in the patching process.
Alongside subnet or AZ failure, it is important to note that servers can be corrupted for a wide variety of reasons. For example, if multiple users try to update a server at once, the server cannot comprehend all the activity and may crash or corrupt. This scenario occurred with one of our clients where one of their non-production servers had been corrupted. This corruption resulted in major downtime, subsequent costs, and created bottlenecks for the development team. With our EC2 HA solution implemented, our client’s Dev team were able to create a copy of the corrupted server where all configurations were replaced automatically with new versions. This ensured a speedy recovery of their servers, greatly minimising their overall downtime, saving thousands in financial and reputational costs.

EC2 HA is one of our key disaster recovery methodologies, and can be used for a single server or a group of servers. As mentioned previously, OS patching does not always go flawlessly. At times it can bring server to an irrecoverable state where server recovery would have to take place from the most recent backup snapshot. After a server recovery all other networks and routing dependency updates need to take place in order to point to the newly recovered server. This is where EC2 HA saves the day! Alongside provisioning the restoration from the backup snapshot, EC2 HA also takes care of the configuration dependencies and makes the restored server fully functional and rapidly available.
Recovery and configuration update playbooks are scenario specific; therefore human error prone. Automating these procedures eliminates the risk of human error, reduces downtime and saves your organisation money.
Furthermore; in a scenario where a server stack needs to be recovered in another subnet because of subnet connectivity issues, EC2 HA will execute the recovery and configuration updates in parallel, vastly increasing efficiency.
Sometimes application latency sensitivity is high, leading to RDS instances having to failover to another AZ. EC2 HA helped our client get their servers into a subnet in the corresponding AZ, therefore resolving their latency sensitivity constraints.
Recapping the Benefits of EC2 HA

• Greatly minimises downtime
• Pre-orchestrated, automated, and event-driven
• Human error reduced
• Little human interaction needed to start up
• Reduces business risk such as reputational damage and customer distrust
• Can restore servers on demand whenever necessary, in a range of disaster scenarios
Talk to a migration specialist
As organisations modernise their cloud environments and prepare for data-intensive and AI-driven workloads, resilience becomes just as critical as scale. Cloud adoption isn’t only about moving workloads into AWS – it’s about ensuring that core systems can withstand failure, recover quickly, and continue operating in the face of disruption.
Cloud Elemental is an AWS Advanced Tier Partner with experience delivering cloud migrations and modernisation programmes for a wide range of organisations operating regulated, mission-critical environments. Our approach focuses on creating cloud foundations that are resilient, secure, and optimised to support advanced workloads, whilst maintaining continuity throughout the cloud optimisation process.
If you’d like to discuss your current environment, explore how our automated solutions can bolster your resilience, or review our cloud migration case studies, speak with one of our migration specialists today.

