
The Challenge
My data was unstructured, diverse file types, scattered formats, unstructured text, and I needed a way to interact with it intelligently, extract insights, categorise it, and automate responses. I needed an AI agent that could:
- Understand my unstructured documents
- Categorise, matrix and tabulate them
- Answer targeted prompts (like listing all files under category B)
- Reduce time wasted navigating my knowledge base
This post walks through how I went from a proof-of-concept to a working system using a stack of powerful tools, each playing a distinct role.
Step 1: POC with NotebookLM & Gemini
To begin, I built a Proof of Concept using NotebookLM, Google’s notebook-focused LLM. Its limit of 200 sources worked for this proof-of-concept. I then integrated Gemini to test how prompting could work with my data. I asked questions like:
- “Summarise the data into categories”
- “Generate a matrix view of this content”
This helped shape how I wanted the final agent to behave, and exposed limitations, such as restricted data ingestion and inconsistent responses when documents were varied in structure. Despite that, I gained clarity on what the agent should do, what kind of answers I expected, and what bottlenecks to eliminate.
Step 2: Choosing the Right FM with Amazon Bedrock
Once the vision was clear, I moved to Amazon Bedrock to access enterprise-grade foundation models (FMs). The playground allowed me to evaluate multiple providers.
After trying various models, I landed on Anthropic’s Claude 3 Haiku, which:
- Gave the most accurate, context-aware answers.
- Handled large token inputs perfect for my large, unstructured files.
- Low latency, suitable for real-time workflows
- Handling moderately large contexts effectively
- Lower cost per token compared to Claude 3 Sonnet or Opus
With the FM selected, I uploaded all my source files to an S3 bucket, ready for vectorisation and knowledge integration.
Step 3: Building a Knowledge Base with OpenSearch + Titan Embeddings
The next step was structuring the unstructured.
- I used AWS Titan embeddings to transform my documents.
- Then built a vector database in OpenSearch to support Retrieval-Augmented Generation (RAG).
- Despite inconsistent data formats, this let me build a searchable, intelligent index.
This laid the groundwork for building a powerful Bedrock Agent that could actually use this knowledge.
Step 4: Customising My Bedrock Agent
With the knowledge base set, I created a Bedrock Agent:
- Connected it to the OpenSearch KB.
- Trained and fine-tuned the orchestrationlogic to return tabular or matrix-style responses.
- Enabled in-memory capabilities, allowing short-term context retention across turns for smoother multi-step workflows.
- This helped in maintaining state, e.g., remembering selected categories in a session.
Example Prompt:“List all documents in a table categorised by topic.”
Expected Output:
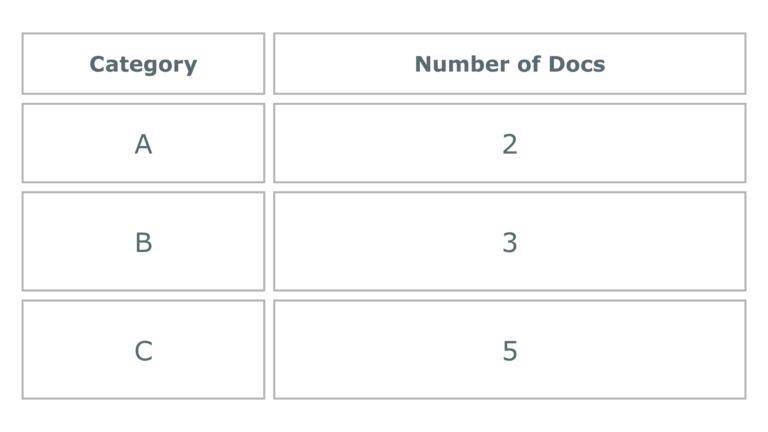
Follow-up Prompt: “Show me the files in Category B”
Agent Output:Returned detailed entries with summaries or content snippets.
This was a game-changer, as it let me query my unstructured data like a clean API, instantly reducing manual digging.
Step 5: Orchestrating Everything with n8n
Once the agent was ready, I needed to integrate it into my workflows. That’s where n8n came in. I used n8n to automate queries and post-process agent responses, as well as:
- Setting up trigger-based workflows, e.g., Creating a Chat message trigger, or recurring reports every day/week.
- Integrating with Slack/Emailto push responses in real time.
- Using custom JS nodesin n8n to transform raw responses into usable dashboards or summaries.
How n8n helped:
- Fully visual, intuitive for building fast prototypes.
- Supports conditional logic, retries, branching and making it great for controlling how the AI agent is used.
- Easy integration with AWS APIs and webhooks.
Final Result: A Fast, Insightful Knowledge Assistant
- My agent now reads from S3, vectorises, retrieves using OpenSearch and responds via Bedrock.
- n8n powers all orchestration, triggers, and delivery.
- I can prompt it with custom instructions, and it responds with structured outputs even from unstructured data.
The result? A smarter way to interact with documents, which is searchable, categorised, summarised, and instantly accessible.
Conclusion
This project showed the power of modern AI tooling when stacked creatively:
- NotebookLM: fast POC validation.
- Gemini: prompted thought framework.
- Bedrock + Titan + Anthropic: scalable, accurate, enterprise-grade LLM agent.
- OpenSearch: a solid RAG base.
- n8n: low-code orchestration superpower.
If you’re dealing with fragmented data and want to turn it into actionable intelligence, this stack may inspire your next build.

This post was written by Sandra Sahnoune, one of our Consultants & DevOps Engineers at Cloud Elemental, as part of our ongoing series exploring how AI is transforming the way we build, ship, and scale cloud solutions. At Cloud Elemental, we’re committed to being at the forefront of innovation with these tools not just for efficiency, but to raise the bar on quality, security, and developer experience across our service offerings.
If you’re looking for a partner to help build cloud-native, AI-enabled solutions, we’d love to hear from you. Get in touch with the team at Cloud Elemental to start a conversation about how we can support your next project.

